Qualification tools
Table of contents
- Criterion: Massive
- Criterion: Artificial
- Criterion: Intent to harm
- Criterion: False or misleading
- Criterion: Illegal
Criterion: Massive
Almost every available and open detection tool to be found relies on Twitter’s API or uses Twitter data. In the rather recent field of bot detection, it seems that social media platforms other than Twitter have been left aside.
Media Scale
Reports often use simplistic ways to assess impact, simply summing the number of followers of known “bad” accounts on social media, or the view count when available, such as on video media. Raw numbers then generate anxiety (“30k views! 13k shares!”), but do not help prioritizing efforts.
The team of the French Ambassador for Digital Affairs offers a way to compensate that tendency: Media Scale. Rather than focusing on the quantitative aspect, it offers a scale of relevance by putting the number of shares in perspective with reference articles shares for a given cultural context.



This more qualitative approach helps give perspective to readers of threat notices that might be further away from the topics, and prioritise their own qualification work.
This resource is open-source and can be used as:
- A dataset.
- A live hosted API:
https://disinfo.quaidorsay.fr/api/media-scale/1.0/around?region=fr&shares=150000. - A chatbot that is already available in our collaboration chat.
Data is currently available for a limited number of countries, but contributions and requests are welcome.
Criterion: Artificial
Almost every available and open detection tool to be found relies on Twitter’s API or uses Twitter data. In the rather recent field of bot detection, it seems that social media platforms other than Twitter have been left aside.
Botometer
By whom?
Botometer (formerly known as BotOrNot) was created by the Observatory on Social Media (OSoMe), a joint project of the Network Science Institute (IUNI) and the Center for Complex Networks and Systems Research (CNetS) at Indiana University. The goal of the observatory is to study and analyze how information is spread on online social media. Botometer is but one of the tools of the OSoMe. The contributors to Botometer are Clayton A Davis, Onur Varol, Kaicheng Yang, Emilio Ferrara, Alessandro Flammini and Filippo Menczer.
What?
Botometer is a machine learning algorithm, which means that it has been trained to determine the probability of an account being genuinely human or bot-like and classify said account on the basis of “tens of thousands of labeled examples”.
Botometer has its own an application programming interface (API) to allow users to directly check the account of their choice. It uses Twitter’s API to find information related to the account and its activity (public profile, public tweets and mentions) and then “extracts about 1,200 features to characterize the account’s profile, friends, social network structure, temporal activity patterns, language, and sentiment” before computing them.
The tool then offers a score “based on how likely the account is to be a bot”. This score goes from 0 to 5 ; the higher the score, the more likely it is for the user of the account to be a bot. A score at 2.5 or around indicates uncertainty as to the nature of the account. The score can be expanded into several more detailed sets of scores, some of them using only language-independent features.
One can also find what is called the “Complete Automation Probability (CAP)”, that is to say the “probability, according to [Botometer’s] models, that [an] account is completely automated, i.e., a bot”. The CAP is calculated based on the estimated overall prevalence of bots, taking into account the fact that humans are much more numerous than bots. It is therefore possible to find an account with a high score but a low CAP.
For more technical information as to its functioning please click here.
What for?
The main goal of the tool is to allow for the determination of the authenticity of the nature of Twitter accounts as accurately as possible.
For whom?
In order to use Botometer, one needs to authentify oneself. Indeed, it heavily relies on Twitter’s API, which requires a logged-in Twitter account. Moreover, one needs to grant the tool permissions to “fetch user profiles and activity” and allow users to block or unfollow users among their own followers and followees through Botometer.
Additional information
The only data stored by Botometer is “the account’s ID, scores, and any feedback optionally provided by the user”. It is not possible for Botometer to make requests on behalf of a user after this user has left the site. However, granting permission to Botometer to block or unfollow users enables posting and profile updates.
Reliability assessment
Botometer being closed source and having been built in 2016 from a US-based dataset, the French Office of the Ambassador for Digital Affairs independently audited the reliability of Botometer for non-American accounts in March 2019.
Methodology
Between the 26th and 28th February 2019, manual annotations were made by 12 French students of Sciences-Po Saint-Germain-en-Laye (M1 level). They were presented with an initial sample of 20 Twitter accounts representing authentic and inauthentic accounts, asked to classify them as pairs of certainty adverbs and authentic / inauthentic types (e.g. “certainly a bot”, “probably a human”…). Each annotation was made by pairs of students and then reviewed by another, independent pair. Feedback was given by experts for the initial 20, and then on demand.
Students were then asked to select and classify another hundred account, with no specific criteria for selection. An exploratory algorithm was then designed and implemented, selecting accounts that were likely to be bots according to the most successful criteria as spotted by the human classifiers. A subset (312) of these accounts were then manually classified, once again by two independent pairs of students. A random subset (~ 80) of these annotations was then reviewed another time by disinformation experts. More information on methodology and results can be found on sismo.quaidorsay.fr.
Annotations were then transformed into numbers for easier comparison with Botometer scores, according to the following table:
| Manual classification | Estimated Botometer score range |
|---|---|
| undoubtedly inauthentic | 4.2–5.0 score |
| apparently inauthentic | 3.8–4.2 score |
| probably inauthentic | 3.2–3.8 score |
| perhaps either | 2.0–3.2 score |
| probably authentic | 1.4–2.0 score |
| apparently authentic | 1.0–1.4 score |
| undoubtedly authentic | 0.0–1.0 score |
This original dataset was largely unbalanced in favour of suspicious accounts, so we added another group of 100 accounts that we know are authentic (friends and celebrities) on May 27th, 2019.
Limitations
Botometer scores of the classified accounts were calculated at a later stage, on May 22nd, 2019. This time difference in computation is a human error. A few accounts were not available anymore, and we excluded them from the analysis, resulting in a slightly lower number. Differences in assessment could also be induced by the time gap (a seemingly inauthentic account in February might become more human-like two months later, and the other way around). In order to mitigate this issue, we ran the Botometer API on timelines and mentions reconstructed for March 1st, 2019, through data scraping. The only limitation to this approach is that some mentions might have been deleted by their authors.
This evaluation was made on a dataset that we built to be highly varied, however it cannot capture the full diversity of both authentic and inauthentic accounts that can be found in the Twitter community. This work does not claim to assess all contexts on which Botometer can be used, but we believe it is the largest third-party assessment available to date.
Results
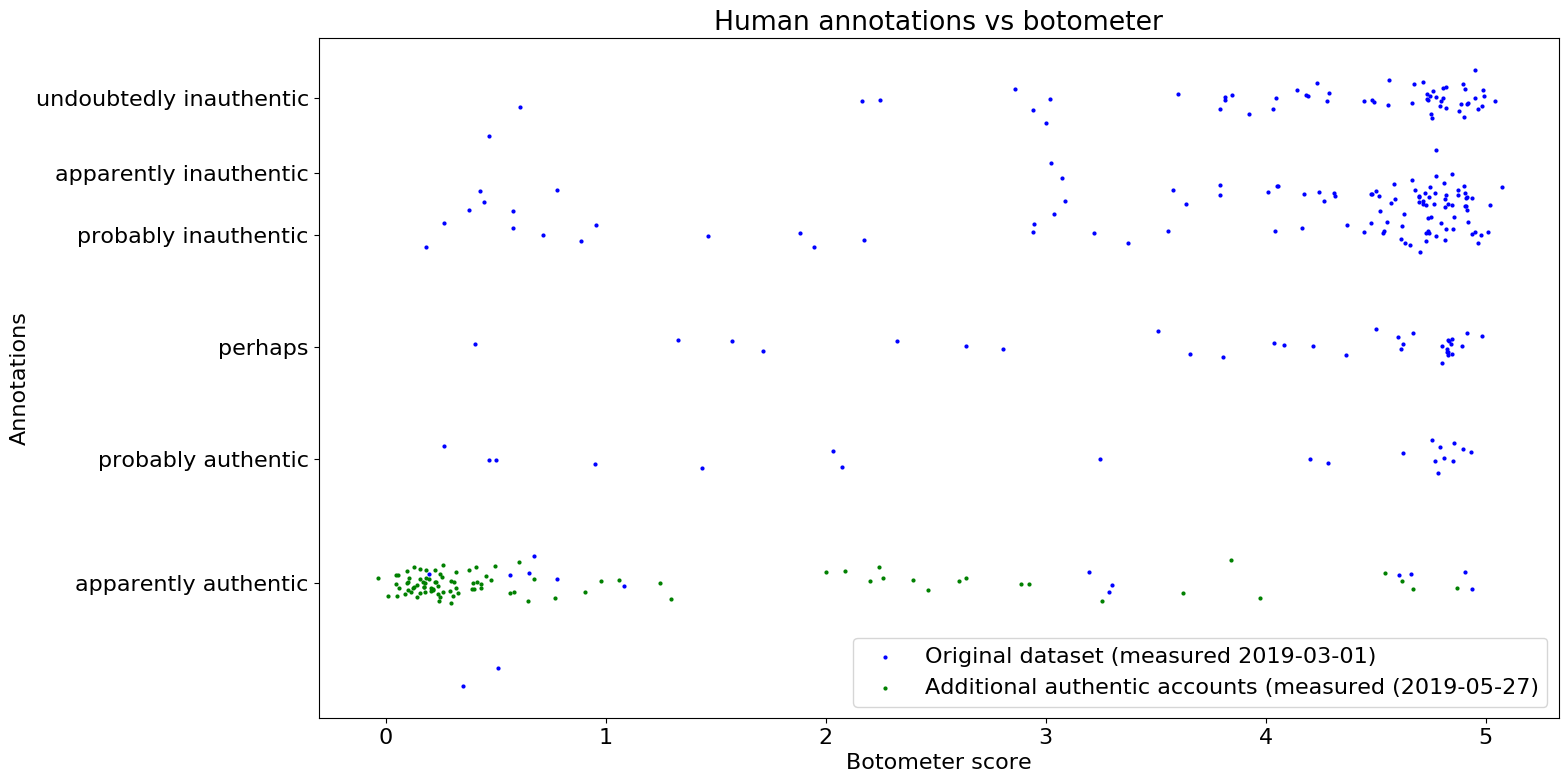
The two main clusters of accounts that were evaluated both as authentic or both as inauthentic by humans and Botometer, indicates that Botometer generally makes guesses similar to humans, even in a non-English context.
Chatbot wrapper
This tool gives users the probability that Twitter accounts that have tweeted a specific content are authentic.
All that a user has to do is send a link to one piece of content to the bot via the “Analysis” channel of our collaboration chat.
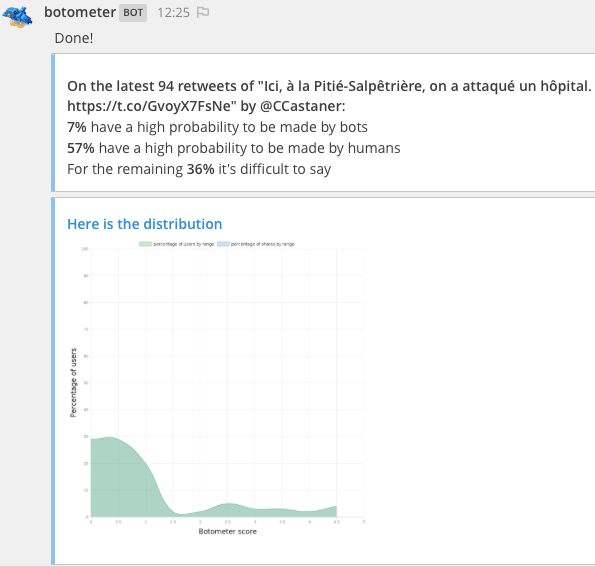
The bot assesses the probability that the accounts that have tweeted said content (up to 100 accounts) during the last seven days are robots.
It displays respectively the percentage of shares by these accounts:
- that have a high probability to have been made by bots
- that have a high probability have been by humans
- for which it is unclear
As well as the percentage of these accounts themselves that are:
- very likely to be bots
- very likely to be humans
- unclear in nature
x0rz/tweets_analyzer
An open-source Python library created by an OSINT researcher that scrapes tweets metadata and analyses the activity of an account. It can output a diagram straight in the terminal, but also provides a base for finer analysis by collecting data.
TruthNest
By whom?
TruthNest is an initiative of the Athens Technology Center (ATC) and its innovation lab. ATC is the project coordinator of the Social Observatory for Disinformation and Social Media Analysis (SOMA).
ATC works on fighting disinformation and TruthNest is one of its two main tools - alongside Truly Media - destined to content verification. Its research is financed by the European Commission and it benefits from funding from Google’s Digital News Initiative.
What?
TruthNest is a tool for “deep Twitter analytics”. Through an app, it allows users to identify suspicious accounts by giving the profile a score reflecting its probability of being automated. It relies on key performance indicators (KPIs), metrics regarding the activity (tweeting density, hashtags, preferred users…) , the network (growth pattern, activity of the main followers…) and the degree of influence (likes and replies received, mentions, context, referrers…) of the account.
What for?
Like Botometer, TruthNest allow its users to determine as accurately as possible whether a Twitter account is automated or human. Its possible use for journalists in the verification process of shared content, sources and accounts on Twitter is highlighted in its official description, as well as its benchmarking and influence indentification potentials. Mainly, its goal is to inform users of suspicious activity of accounts they’re interested in. More than a detection tool, it also allows its users to monitor accounts in almost-real time and to produce then export analyses reports.
For whom?
To use TruthNest, one needs to sign in with a Twitter account. The tool is described as open to a variety of actors, from independant “curious individual[s]” to journalists, investigators and marketing professionals.
Additional information
TruthNest costs from 9€ (gives 20 credits, which translates into 20 analyses) to 149€ (500 credits).
@probabot_
By whom?
This tool was created by web developer and journalist Keith Collins, currently working for The New York Times regarding finances, tech and media matters, among others.
What?
As its Twitter description explains, @probabot_ is a “bot that hunts bots”. It focuses on accounts tweeting about politics that have a Botometer score above 69%. The @probabot account has almost 2 000 followers.
The bot regularly published its results following this format: name of the account + “has a Botometer score of 94.2%, suggesting the account is probably a bot (or bot-assisted)” + status of the account (activated or suspended).
Although the bot account signed in on Twitter in January 2017, it stopped its activity mid-May 2018.
What for?
This tool automatically assessed the probability of automation of specific accounts (see above).
For whom?
Being a public Twitter account, this tool is open to any Twitter user.
Additional information
Creator Keith Collins has a similar project, also using Botometer, called “node-botometer”. More information available here.
@StattoBot
By whom?
The @StattoBot account is anonymous. However, it quotes in its pinned tweet (here used as a longer description) Caroline Orr (@RVAwonk), Ben Nimmo (@benimmo), Andrew Weisburd (@webradius), James Patrick (@J_amesp) and the OSoMe (@truthyatindiana) as references. It is located in the United Kingdom.
What?
This tool is itself a bot and was likely created in October 2017 (date of its first logging on Twitter). It works as an interface system. To obtain the probability of an account being a bot, the user only has to adress a tweet to @StattoBot mentioning the name of the account she or he wishes to investigate but without taggin it. The format used should thus be “@StattoBot AccountName”.
The bot will then reply in two tweets, one with basic statistics on the account (date of creation, total number of tweets, number of daily tweets, number of followers and followees), and another giving the Botometer score of the account.
However, @StattoBot is only partially automated, as it regularly shares and publishes written content, mostly updating the situation of the tool.
What for?
As explained in its description, this tool is meant to be used “to provide some statistics which might help you in forming a judgement” as to whether an account is fake or automated, or not.
For whom?
This tool is open to any Twitter user. Since it uses Botometer, an activated Twitter account is required.
Spottingbot by PegaBot
By whom?
Spottingbot is a project based in Rio, Brazil, relying on and inspired by Botometer. Along with a media literacy campaign, it is the second main part of the PegaBot(Portuguese for Bot Buster) initiative, launched by the Institute of Technology and Society of Rio de Janeiro (ITS Rio), the Instituto Equidade & Tecnologia and AppCívico, a tech company focused on human rights and the use of technology to impulse social change that works with civil society organizations, private actors, politicians and governmental agents on solving social issues.
What?
Created at the end of 2018, the online platform PegaBot allowed its users to analyze the “probability of whether a social profile is a bot or not”. Using Botometer, its experimental and open-source online tool spottingbot welcomes collaboration and indexes information on Twitter accounts (“user”, “friend”, “network”, “temporal”, “total”) to help determine their authenticity.
What for?
The Twitter description of PegaBot soberly explains that the goal of the program is to help users verify if a Twitter account is a bot or not. However, both the online tool and the media literacy campaign aim at educating and raising awareness “on how bots and social media manipulation are related”.
For whom?
Given the early stage of the project, it is difficult to assess exactly the crowd it aims, however it is supposed to be open to everyone.
Additional information
According to official communication, “in two days, the project has gone viral in Brazil and it has been accessed by more than 200 thousand people, demonstrating there is a large demand for awareness regarding how manipulation in social media occurs”.
More technical information can be found here. Wider information on the PegaBot initiative can be found here and here.
Botson
By whom?
Botson was created in San Francisco by engineer and data enthusiast Will Johnson and writer Andy Jiang.
What?
Botson is a navigator (Chrome) extension based on Botometer. Once installed, it thus requires authentification through a Twitter account. From then on, the user will see that on its Twitter newsfeed, “tweets from accounts that have received a “botˮ high score will be blurred and covered with information about that account”, namely this sentence: “We are XX% confident that this tweet is from a bot.” (the percentage being the account’s Botometer score).
Botson also offers a basic overview of metrics of the accounts scored (number of accounts checked and number of bots detected).
The code of Botson is accessible in open source.
What for?
The main goal of Botson is to detect Twitter bots in users’ newsfeeds and then inform said users about the content they are exposed to through their Twitter newsfeeds. It can be considered as a form of media literacy action. Speaking more broadly, the website of Botson explains its engagementin the fight against disinformation and the threat information manipulation can represent : “Now, more than ever in our history, we must be ruthless in discerning the legitimacy of our information. This chrome extension is one step towards a future where bipartisan beliefs and values can co-exist supported by constructive dialogue based on a single reality.”
For whom?
Botson is open to everyone. As the extension relies on Botometer, it can be used on the condition of having an activated Twitter account. Moreover, as a specific Chrome extension, one must have Chrome installed as an Internet navigator.
tweetbotornot
By whom?
Tweetbotornot was developed by assistant Professor at the University of Missouri and Journalism and Data science student Michael W. Kearney.
What?
Tweetbotornot is not exactly a tool but an R package (including reproducible R code, documentation and explanations on its reusable R functions, tests and data sets). It uses machine learning to classify Twitter accounts as bots or authentic.
The function tweetbotornot() works on the basis of Twitter screen names or user IDs that the tweetbotornot user wishes to investigate. It also accepts data returned by rtweet (a tool able to search users and tweets using specific hashtags, measure frequency of said tweets, find trends, get timelines, get a list of all the accounts a user follows or of the accounts following a user, etc.) functions.
It computes users-level data (bio, location, number of followers and friends, etc.) as well as data concerning tweets (number of hashtags, mentions, capital letters, etc. in a user’s most recent 100 tweets).
It then displays the screen name, the user ID and the probability of the account being a bot (from 0 to 1).
Because it uses Twitter’s API, the maximum number of estimates per 1/4 hour is only 180. However, it is possible to use tweetbotornot’s fast model, which only uses users-level data in order to estimate up to 90 000 accounts per 15 minutes. Yet, it is unfortunately less accurate. As explained by the developer:
The default model is 93.53% accurate when classifying bots and 95.32% accurate when classifying non-bots. The fast model is 91.78% accurate when classifying bots and 92.61% accurate when classifying non-bots. Overall, the default model is correct 93.8% of the time. Overall, the fast model is correct 91.9% of the time.
What for?
The main goal of the tweetbotornot() function is to determine the probability that a Twitter account is a bot or not as accurately as possible.
For whom?
The package can easily be downloaded and used by dilettantes as well as professionals. However, the tool relies on Twitter’s API - meaning that users must be authorized to interact with it, which can be done by signing into Twitter while working in an interactive session of R.
DeBot
By whom?
DeBot was created in February 2015 by a group of computer scientists led by Nikan Chavoshi.
What?
DeBot is a real-time bot detection system using an API. Although its code is not available in open source as the method has been patented, it is explained that DeBot relies on activity indicators of Twitter accounts and presumably bots networks.
The system “reports and archives thousands of bot accounts” daily and offers on-demand bot detection. DeBot users can send a maximum of fifty daily requests based on a Twitter screen name (@xxxx) and either a topic, a location or a set of users.
What for?
DeBot is used for both small- and large-scale bot detection, but it also reports bot accounts and produces archives.
For whom?
Any Twitter user with an API key can use DeBot. See more here.
Additional information
“DeBot is an unsupervised method capable of detecting bots in a parameter-free fashion. In March 2017, DeBot has collected over 730K unique bots.”
Student projects and others
Unnamed machine-learning-based bot-detecting algorithm
This algorithm was written in 2017 based on the Twitter Bot program, which produces automated posts, spams and follows Twitter users. It uses machine learning to determine whether an account on Twitter is a bot or not, on the basis of selected features. It has an AUC over 95%.
More information can be found in this repository.
Twitter Bot Detector
This project uses the Twitter API to collect tweets within the United States and analyze them “using algorithms based on posting times and other factors to determine probability of each user being a bot”.
TwitterBotDetection
After manually collecting Twitter profiles (real users and bots) and listing checked bots on a wiki (botwiki.org) and a Twitter bot repository (Twitter.com/botally/lists/omnibots/members), students wrote a script “to harvest each users’ profile and posts via the Twitter API”. They then extracted data (followers count, friends count, favorites count, name, created date, screen name, tweets, tweet frequency, lexical diversity, sentiment etc) to try and classify the accounts as bots or authentic.
More information can be found in this repository.
Twitter API
The Twitter API allows users to block, mute or even report accounts. It also can be used to get trends in a specific geographic area. On a corporate level, one interesting aspect of the API can be its ability to show - and thus allow users to monitor - data regarding favorites, retweets of, and comments on public tweets.
However, if data is made available to governmental entities, the situation has to be reported and manually reviewed.
BotDetection
What?
BotDetection (repository available here ) is a “Reddit bot that detects other bots”.
It works thanks to a basic feed-forward Artifical Neural Network (ANN) “that can be used to detect comment spambots on Reddit”. Using machine-learning, BotDetection can classify “most users with high confidence”. Users can open the detector.py interface and run the isABot function with any username. They will then be provided with a number ranking from 0 to 1 representing “how much the Neural Network thinks the user is a bot”.
What for?
The first mission of the tool is basic bot detection upon user request.
For whom?
BotDetection is free and its code is open source.
However, to use this tool, one needs to have previously installed softwares like PRAW (Python Reddit API Wrapper), NLTK (Natural Language Toolkit) and SciPy, and also needs to know a little bit about code (especially Python).
Criterion: Intent to harm
- Hatemining is a troll detection and hate speech detection in German that works with an API. It is a research project of the European Research Center for Information Systems (ERCIS).
- Perspective is an experimental API initiated by Google Jigsaw.
Criterion: False or misleading
Image
Forensically
Forensically is a web app providing digital image forensics (analysis). It includes clone detection, error level analysis, meta data extraction and more.
Video
InVID
By whom?
InVID is a project co-funded by the European Commission started in January 2016 and achieved in December 2018.
What?
It focused on video verification of “eyewitness media”, with the goal to develop an innovative verification platform “to detect emerging stories and assess the reliability of newsworthy video files and content spread via social media”. Indeed, editing softwares and content management tools increasingly allow for the spread of fabricated, manipulated, deceiving videos. Content verification is costly and time-consuming for news outlets.
The InVID platform was built to help “detect, authenticate and check the reliability and accuracy of newsworthy video files and video content spread via social media”.
It works through a verification application, a mobile application, a visual analytics dashboard as well as a verification plug-in (among others) which offer online services for video fragmentation, reverse image search and annotation, a logo detection tool, a context aggregation and analysis tool as well as a rights management service.
What for?
InVID allows its users to quickly verify video content and make sure that it is rights-cleared and readily available. It helps avoiding the spread (by mistake) of false information or fakes by media outlets.
For whom?
Mainly, InVID is useful for “broadcasters, news agencies, web pure-players, newspapers and publishers” because it allows them “to integrate social media content into their news output without struggling to know if they can trust the material or how they can reach the user to ask permission for re-use”.
Additional information
InVID is a follow-up project of RevealEU. WeVerify is a follow-up project of both InVID and RevealEU.
Montage
Montage is a web app allowing for collaborative viewing and timecoded annotation of YouTube footage.
Montage is an open-source app by Meedan and Google Jigsaw.
Social media content
Truly Media
By whom?
Truly Media was co-developed by the innovation lab of the Athens Technology Center (ATC) as well as Deutsche Welle Innovation. With TruthNest, it is one of the two main tools of ATC’s iLab in fighting disinformation. Truly Media can be considered as a follow-up project of several other research projects linked to the European Commission. It is funded by the Google Digital News Initiative.
What?
Truly Media is an online collaboration platform working on the verification of digital content on social networks. Users can monitor social networks, gather information from various sources, collaborate, use effective verification tools, extract and visualize information, etc. Information and content can be organized in collections and shared quickly among users.
What for?
Truly Media was created to help with the verification of “digital (user-generated) content residing in social networks and elsewhere”.
For whom?
The main targets of the project are journalists and human rights workers and investigators, ie actors who helped in its design and development.
Additional information
On 8 April 2019, Truly Media officially announced its collaboration with the European Science Media Hub (ESMH).
CheckMedia
Claims
Fact-Check Explorer
Fact-Check Explorer is a Google search engine specifically designed to browse and search for fact-checks. It allows users to search topics or statements by keywords and displays “a list of matching claims and the corresponding fact checks” sortable by languages. It also offers an overview of recent fact-checks, accessible through a button on the main search page.
Datasets
Data sources that can be used as a base for fact-checking
data.gouv.fr
data.gouv.fr is a public platform developed by Etalab and created in 2011. It allows the publication and download of public datasets. Topics covered are Agriculture & Alimentation ; Culture & Communication ; Accounts, Economy & Employment ; Education, Research & Formation ; International & Europe ; Environment, Energy & Housing ; Health & Social ; Society, Law & Institutions ; Territories, Transport & Tourism. It also publishes how and by whom datasets were used.
European Data News Hub
Through a datajournalism website, the Agence France Presse (AFP), the ANSA (Italian press agency) and the Deutsche Presse-Agentur (DPA) share articles (in five languages), graphs, pictures and explanatory videos on topics related to the European Union. Data is free and open, but also reliable.
In the future, EDNH will open to other media outlets and will allow users (citizens) to answer surveys on salient European issues, which will then be translated into readable data.
EDNH is independent and funded by the European Commission.
Criterion: Illegal
In France
Each of these characteristics can qualify a political ad or an issue-based ad as illegal. Since they are only valid within French jurisdiction, they are described in French.
Publicité politique en période électorale
La publicité commerciale à des fins de propagande électorale est interdite en période électorale, c’est-à-dire jusqu’au jour de l’élection et dans les six mois pleins qui la précèdent, par tout moyen de communication audiovisuelle ou électronique.
Par exemple, si le premier tour a lieu le 28 août et le second tour le 2 septembre, il est interdit de payer pour mettre en avant un parti, une candidate ou en critiquer d’autres du 1er février au 2 septembre, inclus.
Peines encourues
Un an de prison et 15 000 € d’amende pour un‧e candidat‧e ayant demandé ou autorisé de la publicité commerciale. Si une liste électorale a été constituée, seule la tête de liste est concernée.
Violation de la période de silence
Toute communication politique est interdite en période de silence, c’est-à-dire à partir de la veille du scrutin à minuit, par tout moyen de communication. Cela inclut notamment les commentaires et sondages.
Par exemple, si le scrutin a lieu le samedi en outre-mer et le dimanche en métropole, il est interdit de communiquer des sondages à destination de la Guyane à partir du vendredi à minuit heure locale, et d’émettre un commentaire sur les opposants en métropole à partir du samedi à minuit heure d’Europe centrale.
Peines encourues
3 750 € d’amende pour toute infraction.
- Article L89 du Code électoral.
Introduction d’un élément polémique nouveau
Il est interdit aux candidats de révéler « un élément nouveau de polémique électorale » à un moment trop proche de la fin de la campagne électorale si cela implique que les candidat‧e‧s touché‧e‧s ne pourront pas « y répondre utilement ».
Peines encourues
Aucune peine spécifique n’est prévue pour ce cas.
Sondages non conformes
Il est interdit de publier des sondages d’opinion si leur objectivité, leur qualité et leur authenticité n’a pas été garantie par la Commission des Sondages. L’entité publiant ou diffusant les résultats d’un sondage doit avoir soumis une déclaration à la Commission, et que celle-ci y ait souscrit. Ces déclarations sont accessibles en ligne.
- Article 2 de la loi n°77-808 relative à la publication et à la diffusion de certains sondages d’opinion.
- Article 7 de la loi n°77-808 relative à la publication et à la diffusion de certains sondages d’opinion.
Peines encourues
75 000 € d’amende pour la réalisation, la publication ou la diffusion d’un sondage non-conforme.
- Article 12 de la loi n° 77-808 relative à la publication et à la diffusion de certains sondages d’opinion.
Financement étranger
Seules les personnes physiques françaises ou résidant en France peuvent faire des dons à un parti politique ou à une campagne.
- Article 11-4 de la loi n°88-227 relative à la transparence financière de la vie politique.
Peines encourues
Trois 3 ans de prison et 45 000 € d’amende pour bénéficiaires et donateurs.
- Article 11-5 de la loi n°88-227 relative à la transparence financière de la vie politique.
Financement par une personne morale
Les seules personnes morales pouvant financer ou donner à des partis ou groupements politiques sous quelque forme que ce soit (donc y compris une publicité) sont des partis ou groupements politiques français.
Par exemple, le paiement de publicités sur les réseaux sociaux mettant en avant une candidate française par un parti britannique est illégal.
- Article 11-4 de la loi n°88-227 relative à la transparence financière de la vie politique.
Peines encourues
Les bénéficiaires et les donateurs risquent trois ans de prison et 45 000 € d’amende.
- Article 11-5 de la loi n°88-227 relative à la transparence financière de la vie politique.
